
Analyse des données GAFAM: Google
Publié le 3 novembre 2020, par Richard Carlier
Série: Datas from GAFAM
#data #gafam #google
Étant sans doute un peu plus consommateur de Google que des autres services (qui a dit comme tout le monde ?), les données m’inquiètent un peu par leur quantité…
On y va…
On récupère quoi ?
Un lot de 15 fichiers zip. Certains très lourds, puisque contenant les vidéos de ma chaîne Youtube (et encore, je n’ai que peu de vidéos publiées pour l’instant), et mon drive.
Une fois dézippé, de nombreux dossiers, aux noms explicites:

En ce qui me concerne, 172 dossiers, 335 fichiers, pour un poids total de 1,1 Gigaoctets… après avoir retiré les vidéos et les documents du drive. Quand même…
En terme de types de fichiers:
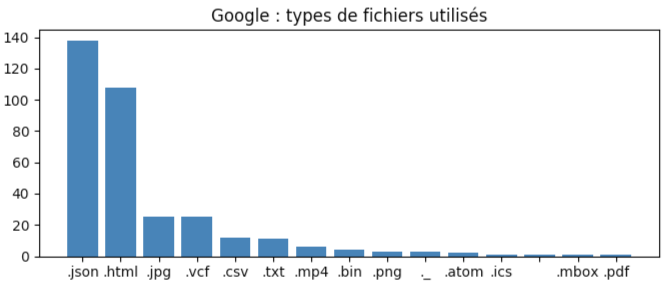
Le format .json prédomine, le .html me surprend un peu plus, mais je ne vois pas ce qu’il fait en si grand nombre dans mon archive. Explication ci dessous.
Le reste me parait bien classique (rappel: .vcf pour le carnet d’adresse, un fichier par contact).
Les surprises…
Ce qui interpelle tout de suite, c’est la présence d’un fichier nommé archive_browser.html à la racine des éléments.
Cliquez dessus pour être bluffé:
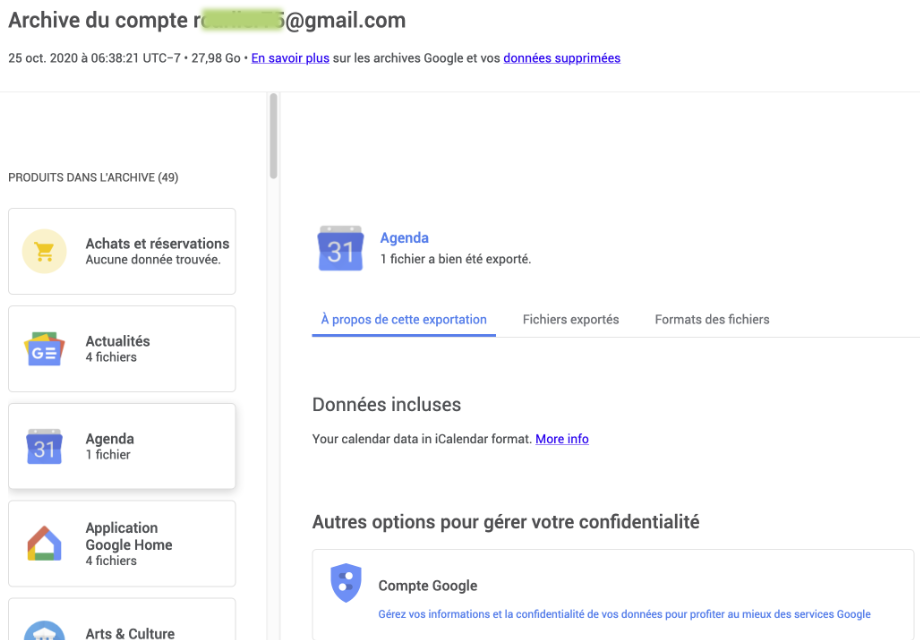
Il s’agit ni plus ni moins d’un mode d’emploi de nos données…
Y sont inclus des explications sur les données, des liens vers les fichiers, des liens vers leurs sources, des liens vers des compléments d’infos sur le format et/ou la structure du fichier, la possibilité d’aller les gérer, c’est à dire demander à Google leurs suppressions, etc…
Redoutable d’efficacité, surtout bien sûr pour le grand public.
Disons le: bravo Google.
Plus ou moins logique, surtout dans mon cas, beaucoup de fichiers sont vides, ou ne contiennent que des entêtes – je n’utilise pas tous les services Google…
Que pourrions nous étudier ?
Les fichiers les plus lourds:
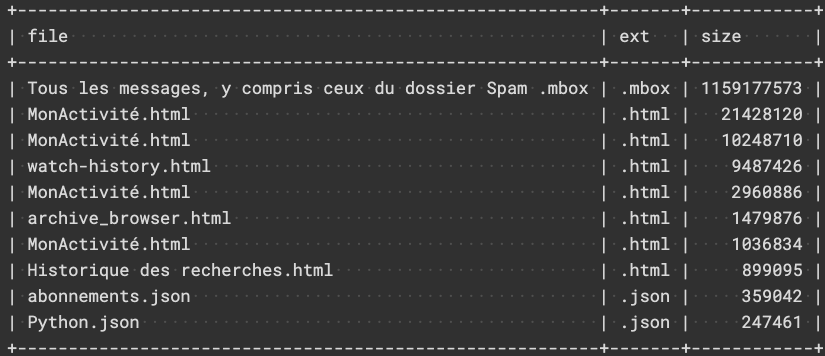
On ne peut pas le nier, le fichier le plus lourd est celui qui contient les messages (et sans doute les pièces jointes). Et peut donner l’occasion d’étudier ma correspondance, le rythme des messages aux uns et aux autres, etc.
Vu les noms, j’ai beaucoup d’activités. Chaque fichier MonActivité.html est en fait réparti dans des dossiers aux noms explicites (Recherche, Shopping, …). Sous forme .html, la moins facile à exploiter pour moi, mais la plus facile à visionner pour le grand public. Au moment de la demande, j’avais laissé par défaut, mais j’avais le choix du format d’export pour un grand nombre de données. Pour les thématiques qui m’intéressent, je ferais peut-être un ré-export dans un format .csv ou autre, plus facile à manipuler (encore que, joueur, partir du html est toujours possible, mais plus long).
M’intéressant aussi, mes abonnements youtube me permettront de m’organiser dans mes listes de favoris (le Python.json ci dessus). Je suis gros consommateur de Youtube (ce qui explique que Netflix ne fasse pas parti de l’étude, je n’y suis pas abonné…). Là encore, un ré-export ou, mieux, étudier l’API permettant de travailler en direct serait plus efficace.
A suivre…