
Analyse des données GAFAM: Amazon
Publié le 16 novembre 2020, par Richard Carlier
Série: Datas from GAFAM
#amazon #data #gafam
Un peu plus longues à arriver, les données Amazon sont passées à la loupe…
On récupère quoi ?
Un lot de 54 fichiers zip, qui une fois dézippé nous donne 45 dossiers bien nommés.
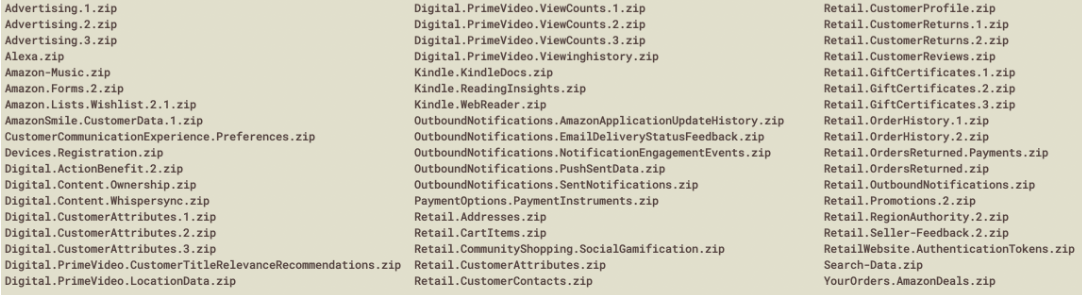
En ce qui me concerne, 45 dossiers, 578 fichiers, pour un poids total de 14,9 Mégaoctets…
En terme de types de fichiers:
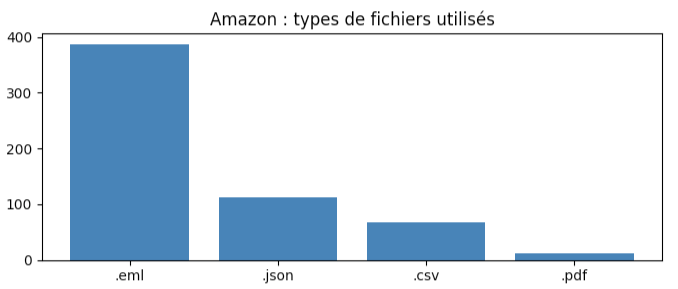
La prédominance des .eml m’a un peu surpris, mais surtout car je ne me souvenais plus qu’ils permettent de stocker… des emails. J’ai donc les 387 mails reçus d’Amazon depuis 2013…
Les 112 fichiers .json et 67 petits .csv sont classiques pour contenir des données, les .pdf semblent contenir des informations textuelles (historique de mes adresses de livraisons par exemple, pas forcément facile à exploiter mais de peu d’intérêt en soi) ou des instructions (donnant la structure de certains fichiers, ce qui est pour le coup intéressant).
Les surprises…
Ce nombre de fichiers aurait pu être rassemblé en un seul zip, plus pratique à récupérer. Mais le fait de les séparer permet de ne récupérer que ceux que l’on souhaite exactement. Vu que je voulais tout, j’ai donc du télécharger un par un les 54 fichiers (avant de les dézipper un par un donc, en espérant n’en avoir oublié aucun):

Un peu pénible.
Également pénible, et curieux, les fichiers numérotés, qui génèrent des dossiers numérotés, composés de fichiers aux noms identiques, mais aux contenus différents…
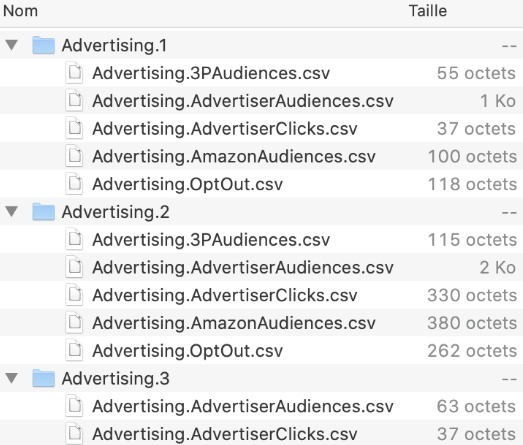
Est ce qu’ils représente la suite? Des périodes différentes? Des infos différentes? Aucune explication n’est donnée… et les ouvrir ne donne pas grand chose à vue de nez. Une chose est sûre, ce n’est pas leur poids qui justifie de les découper…
Bref, rien n’est fait pour nous simplifier la vie…
Que pourrions nous étudier ?
En excluant les e-mails (qui représentent la correspondance, donc un objet d’étude en soi), les fichiers les plus lourds:
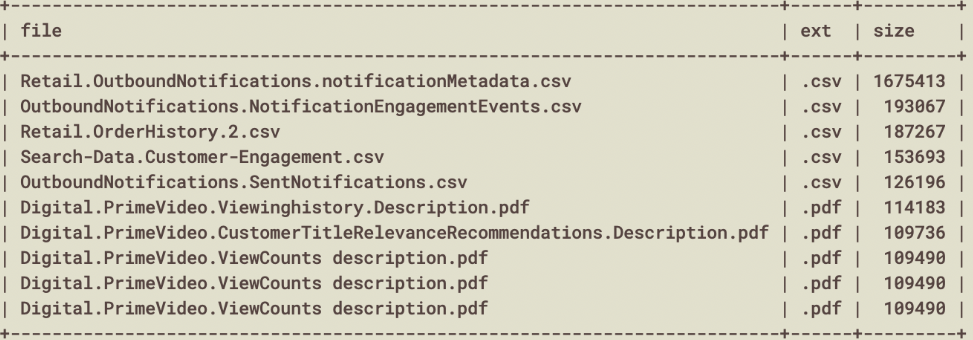
Le plus lourd, « Retail.OutboundNotifications.notificationMetadata.csv » correspond à priori à une sorte d’index des emails
Les PDF (en bas de la liste ci dessus) sont en fait des explications sur certains datasets, en 10 langues…
Amazon est surtout une boutique, les achats et leurs notifications sont donc des pistes naturelles.
Ce qui pourrait l’être tout autant, c’est justement le reste: qu’Amazon collecte exactement en dehors des achats proprement dit.
Vu le nombre et l’organisation des fichiers, j’ai peur que ce soit consommateur de temps.
A voir…