
Whatsapp,
récupération et analyse de données
Publié le 26 janvier 2021, par Richard Carlier
Étude personnelle
#gafam #heatmap #python #whatsapp #wordcloud
Un peu en marge de ma série sur les GAFAM, les données issues de Whatsapp sont intéressantes à étudier.
Si les récupérer est assez simple (on va détailler), les fichiers sont par contre un peu plus subtils de par leur (non) structure.
Et pouvons nous vraiment laisser ces données sans une petite analyse?
Allons-y.
Récupérer les données
Il y a avec Whatsapp plusieurs méthodes de récupérations:
- en invoquant le RGPD, comme expliqué sur la page comment demander ses informations de compte.
- via une API, qui semble réservée aux comptes Business auquel je n’ai pas accès
- via un export depuis l’application, solution que l’on va retenir ici.
Posons déjà les limites de l’export de données : il faut le faire pour un fil de discussion précis.
Si vous voulez tout, la méthode RGPD est sans doute préférable. Je viens de lancer la demande, et actualiserais cet article si besoin en fonction de ce que je recevrais.
Pour l’export:
- Ouvrir l’app Whatsapp (il semblerait que ce ne soit pas possible depuis la version web…) et choisissez la discussion que vous voulez récupérer.
- Un menu (dans mon cas, quelques têtes en haut à gauche) permet d’accéder à des options, dont, tout en bas, Exporter la discussion. On peut alors choisir ou non de joindre les médias

Pour du floutage… c’est du floutage… confidentialité oblige…
Une fois l’export réalisé, on obtient un fichier zip, avec dedans un fichier texte _chat.txt et les médias diffusés (image, vidéos…).

Moins floutées celles-ci…
Analyser les données
Si les images rappellent des souvenirs sympas (j’ai repris le fil de la compétition Zéro Corona), c’est bien sûr le fichier texte qui nous intéresse ici.
A quoi ressemble le fichier?
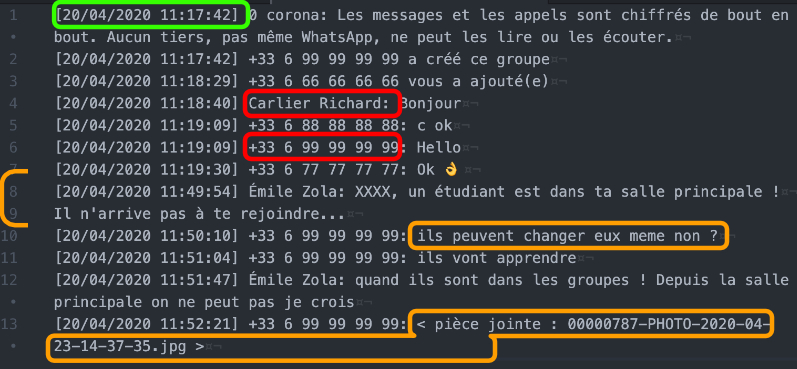
Le fichier est une succession de lignes, regroupant 3 types d’informations:
- la date, en vert ci dessus, sous la forme
[20/04/2020 11:17:42], pas un format des plus simples mais on a l’habitude avec les dates d’avoir de tout… - l’expéditeur du message, en rouge, suivi de
:et pouvant être sous son nom (Émile Zola étant une forme anonymisée), ou sous son numéro de téléphone (+33 6 99 99 99 99 étant une forme également anonymisée…). Si l’utilisateur est dans votre carnet d’adresse, ce sera le nom, sinon le numéro… - le texte du message, en orange, qui démarre après le nom de l’utilisateur, et pouvant aller jusque à la fin de la ligne, ou s’étaler sur plusieurs pour les messages de certains bavards…
- si une pièce jointe est présente, son nom est glissé à la place du texte (et la pièce présente dans le dossier). A priori en cas de pièce jointe elle occupe l’intégralité du message
Il est vrai qu’un format JSON est plus facile à analyser, mais pour suivre une discussion ce format n’est pas trop mal.
Conversion en JSON via Python
Pas trop de piège dans la conversion. Il suffit de scanner ligne à ligne, et si la ligne commence par une date entre crochet c’est que c’est un nouveau message.
En même temps, aucun piège? Hum!
Les téléphones semblent séparés par des espaces, mais ce sont en fait des espaces insécables, ce qui nécessite un traitement particulier…
La solution python la plus simple semble être de nettoyer tout ce qui n’est pas dans la base ascii:
str = str.encode("ascii", "ignore").decode()
Une série de .split() plus tard, et nous obtenons un fichier json (ou csv, ou tout autre format) permettant une analyse plus fine…
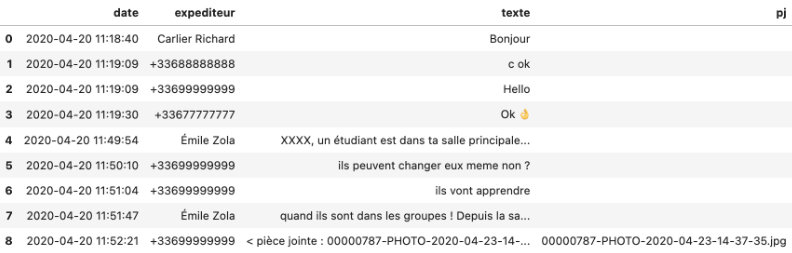
On y voit plus clair quand même !
Pour la suite, j’ai revu l’anonymisation des données pour remplacer par les initiales; et ajustés les numéros de téléphone.
Un peu de dataviz
A partir des données préparées, il devient possible d’en tirer quelques visualisations…
Pour resituer dans le contexte:
- une compétition de 130 élèves (Master 2 Expert en stratégie digitale de Digital Campus Paris),
- étalée pendant une semaine (du 20/04/2020 au 24/04/2020),
- encadrée par 5 professeurs,
- à distance,
- et utilisant Whatsapp pour discuter entre professeurs donc.
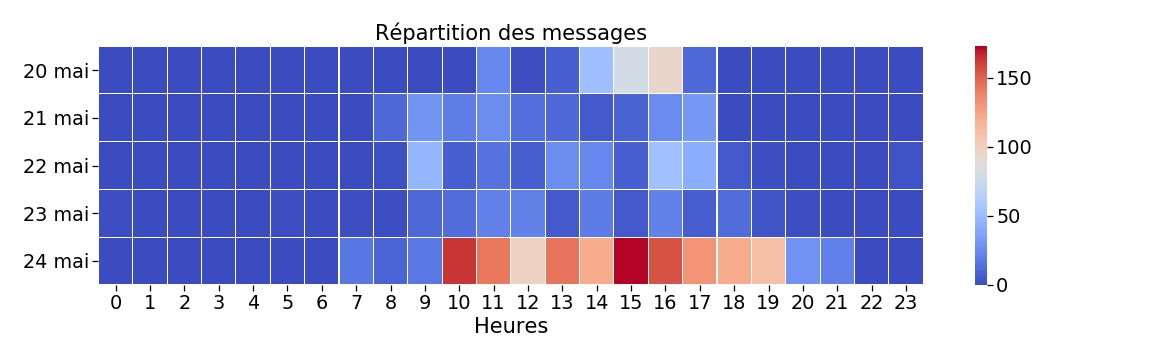
Quand avons nous envoyé des messages ?
En étudiant le nombre de messages par jours et par heure, nous constatons (sans surprise?)
- aucun message la nuit, entre 22h et 7h du matin…
- des échanges importants en fin de première journée pour faire le point après le lancement des sujets
- une activité intense le vendredi entre 10h et 19h, jour de la présentation
- et après 19h le vendredi pour débriefer entre profs (et avec des commentaires évoquant la bière, l’apéro, les pizzas et autres Animal Crossing…)
On ne devrait pas forcément comparer la quantité de messages par profs (nous n’avons pas le même rôle dans l’équipe). Mais ne passons pas à côté d’une heatmap comparative… c’est vrai, je me suis donné tellement de mal à la caler celle là…
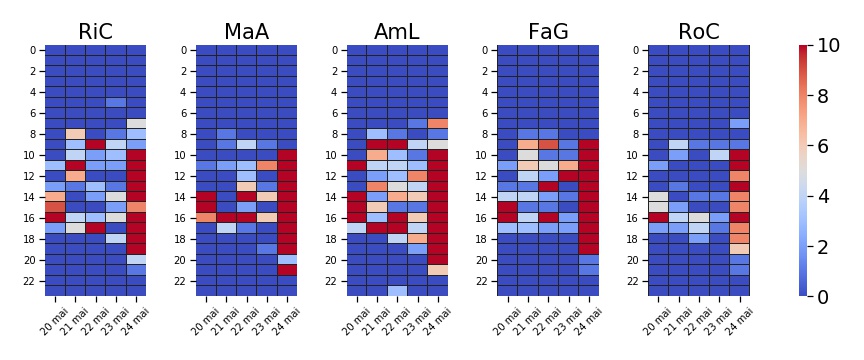
Ce qui à la réflexion n’est pas forcément le meilleurs moyen de comparer l’activité de chacun…
Un bon histogramme… et AmL gagne haut la main (en charge de la gestion de projet, donc logique) !
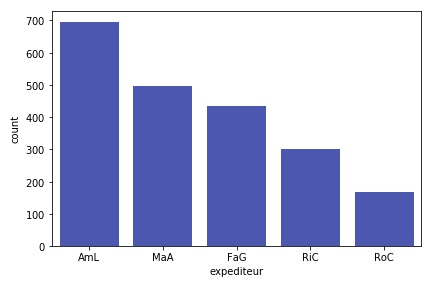
Bien entendu, ce n’est pas la quantité qui compte, mais la qualité.
Donc, le nombre de message importe peu, ce qui est intéressant est ce que l’on met dedans…
Et qui dit quoi ?
Voyons au niveau de l’équipe:

A l’échelle de l’équipe, ressortent des mots finalement bien sympathiques :
groupe, question, brief, Merci, Haha, non, pièce jointe...
Au niveau individuel maintenant:

Au niveau individuel, je vous laisse analyser… voici les mots les plus fréquents de chaque membre:
RiC : groupe, DT, ok, dit, faire, brief, mail, crieur... MaA : oui, pièce jointe, ok, bien, jointe PHOTO, PHOTO jpg, groupe, DA... AmL : Oui, groupe, Merci, Mdr, brief, Non, bien, Ahah, session, faire... FaG : Haha, groupe, bien, Oui, UX, point, eux, pense, question, Hahaha... RoC : groupe, question, brief, Merci, faire, chez, Haha, non, don, pièce jointe...
Aller plus loin dans l’analyse n’aurait qu’un intérêt limité, mais je suis sûr qu’il y aurait encore plein de chose à tirer de ce fil Whatsapp.