
Open Data et nettoyage de données…
Publié le 18 novembre 2020, par Richard Carlier
Open Data
#datacleansing #infogreffe #nettoyage de données #OpenData #python
Préparant activement un cours de python dans un cadre de data science, je m’intéresse aujourd’hui à la récupération de données.
Pour ce faire, l’OpenData est un sacré fournisseur: gratuité, variété, quantité, qualité et pérennité…
Mais… je viens d’écrire qualité et pérennité? Affinons un peu.
Note: initialement publié sur mon blog le 29 janvier 2020, j’ai l’ai déplacé sur datas.fun où il a plus sa place, et légèrement ajusté…
Open Data
Si l’on reprend la définition de Wikipédia, les données ouvertes sont des données numériques dont l’accès et l’usage sont laissés libres aux usagers. Elles peuvent être d’origine publique ou privée, produites notamment par une collectivité, un service public, un collectif citoyen ou une entreprise.
En simplifiant: nos services publics mettent à disposition des données pour que l’on puisse s’en servir. Et il est vrai que, sur le papier, c’est géant.
Cela m’évoque:
- Gratuité: la plupart des sources sont gratuites, en accès libre. Certaines API nécessitent d’être inscrit.
- Variété / Quantité: les jeux de données sont souvent importants, et permettent des usages intéressants. Dans mon cas, c’est quand même mieux de faire travailler mes élèves avec des vraies données, par nature plus réalistes que pourraient l’être des données aléatoires…
- Qualité: étant publiées par les sources officielles qui les produisent, les données sont donc brutes, non biaisées, fiables, ne passant pas par le prisme de journalistes ou autres sociétés commerciales… (oui, j’ai bien noté la potentielle naïveté de cette phrase… mais le propos n’est pas là)
- Pérennité: il me parait difficile de me dire que d’ici quelques années les sources vont se tarir.
Mais.
Si on aborde les aspects purement techniques, et c’est mon propos, qualité et pérennité sont beaucoup plus discutables.
Nous parlons bien de formats de fichiers, de formats de données, et autres fantaisies.
Cas pratique
Mon cours de python (langage fortement utilisé dans le traitement des données) s’adressant à des personnes susceptibles de chercher du travail ou un stage à l’issu de leur formation, j’ai donc décidé de les faire travailler avec des jeux de données liés au monde du travail.
La base de données SIRENE étant un peu compliquée à manipuler dans le cadre d’un cours (5.14Go ce qui ne me fait pas peur outre mesure..) je me suis tourné vers Infogreffe (toujours Wikipedia: GIE éditant depuis 1986 le service de diffusion de l’information légale et officielle sur les entreprises, notamment le Registre du commerce et des sociétés).
En bref, la liste des sociétés commerciales immatriculées au registre du commerce et des sociétés. Et plus particulièrement les listes de sociétés nouvellement créées, et donc susceptibles de recruter des stagiaires.
En me rendant sur leur site, j’ai trouvé les jeux de données année par année depuis 2012. En prenant le fichier 2020 j’ai suffisamment de matière pour mes exercices.
Mais par curiosité, je n’ai pas pu résisté à ouvrir les autres…
Analyse des données
Première étape, rapatrier les fichiers de toutes les années.
493,2 Mo, répartis en 9 fichiers (un par année), tous au format CSV (ça, c’est bien).
- entreprises-immatriculees-2012.csv
- entreprises-immatriculees-2013.csv
- entreprises-immatriculees-2014.csv
- entreprises-immatriculees-2015.csv
- entreprises-immatriculees-2016.csv
- entreprises-immatriculees-2017.csv
- societes-immatriculees-2018.csv
- societes-immatriculees-2019.csv
- societes-immatriculees-2020.csv
Pour une raison quelconque (appelons cela l’instinct du data scientist qui sommeille en moi; ou plus modestement l’habitude), avant de me lancer dans un script d’importation, j’ai voulu vérifier la cohérence des structures d’année en année.
Je parle d’instinct? Euh… en fait, cela saute aux yeux: entre 2017 et 2018 le format des noms de fichier à changé.
Je me suis donc dit: hum. (Il m’arrive d’être concis, quand je me parle…)
Donc, m’attendant à un soucis entre 2017 et 2018, j’ai commencé par pousser l’analyser de ces fameuses structures. Précisons, si besoin, que c’est toujours par la compréhension des structures que l’on commence face à un fichier inconnu…
Quoi de mieux pour cela qu’un petit script python…
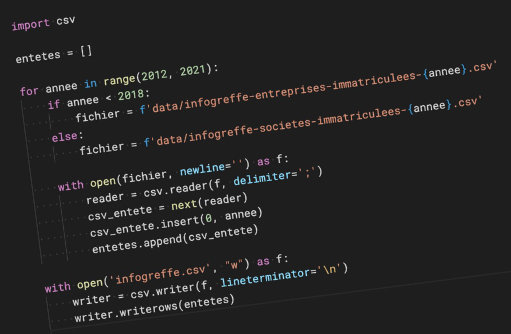
L’idée est de simplement charger chaque ligne d’entête de chaque CSV, d’ajouter l’année en première colonne, et d’exporter le tout dans un nouveau CSV…
Suivi d’un import dans LibreOffice, et un copié/collé avec transposition.
Résumons simplement en une image:
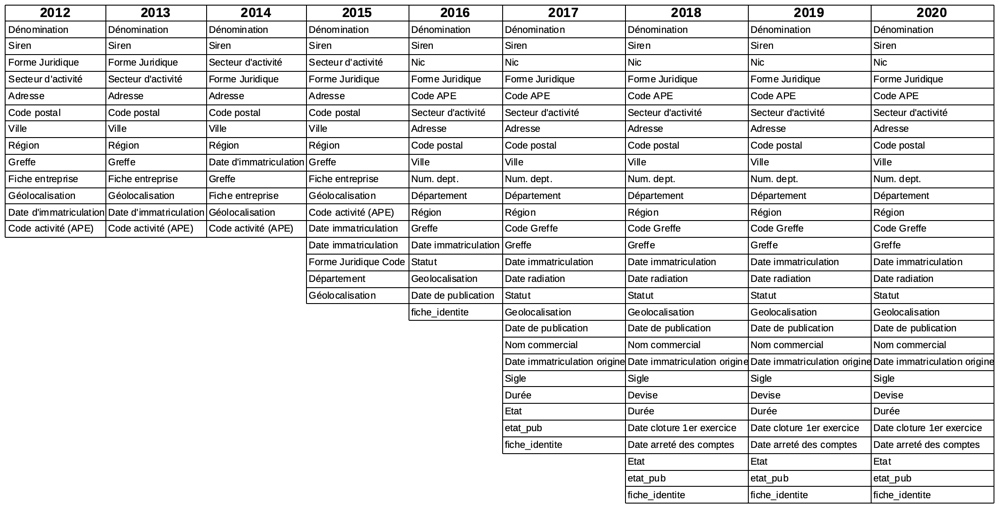
Au premier coup d’oeil, ce qui saute aux yeux est l’évolution du nombre de champs.
Mais en affinant (un petit coup de zoom), je constate une multitude de soucis structurels:

Donc:
- Pas le même nombre de champs. Ça, pourquoi pas, on peut plutôt se réjouir qu’Infogreffe nous donne plus de matières…
- L’ordre des champs (entre 2013 et 2014 principalement…) a changé. J’avoue que, si ce n’est sans doute pas le plus gênant, je ne comprends pas.
- Orthographe des champs. Le champs Géolocalisation a, en 2016, perdu son accent pour devenir Geolocalisation. Alors que Région l’a conservé, ce qui ne me parait pas cohérent.
En poussant l’analyse, les données aussi me réservent des surprises. Ainsi, pour le même jeu de données, 2020 (mais je présume les autres aussi) certaines dates sont stockées sous une forme ‘2019-06-01′ (date de publication) ou sous une autre ’12/31/2020’ (date de clôture). Qu’il y ait eu un changement de tous les formats de date entre une année et une autre peut se comprendre, mais que certaines dates d’un même jeu soient différentes… Bon, c’est clair, on a toujours des problèmes avec l’importation de champs date…
Je me suis arrêté là, j’ai peur… surtout de perdre du temps dans mon cas. Je ne ferais donc pas le script de conversion prévu au départ pour unifier dans une même base les 9 ans. D’autant qu’il faudrait tenir compte des données issues des fermetures d’entreprises…
Mais que cela ferait un bel exercice… (phrase à l’intention de mes étudiants).
Conclusion
Précisons tout de même que je n’ai rien à reprocher à Infogreffe en particulier. Peut être manque-t-il un fichier expliquant la structure des fichiers, cela simplifierait le travail.
Le gros soucis, est que j’ai trouvé le même genre de problèmes sur de très nombreuses sources ouvertes.
Ou non ouvertes d’ailleurs.
Et que je ne suis pas le seul.
Un article du Harvard Business Review (11/9/2017… ou 2017-09-11) évoque que seulement
3% des données des entreprises satisfont aux normes de qualité…
Autre article intéressant, Le Monde Informatique (29 Mars 2016, ou 1459202400)
Les data scientists font plus de nettoyage de données que d’analyse…
Que dire de plus…